Here's a little revision:
Cytoscape.js is unsmoothed by garden variety TLC. Its attendance has probably been a series of academic idea space grabs deep in the theory.
Looking around, here are some compound nodes and some ink flowing yay far downstream, nice concept. Apparently this has something to do with biology. You can almost see the frog legs here:

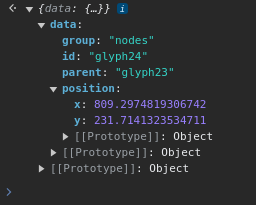
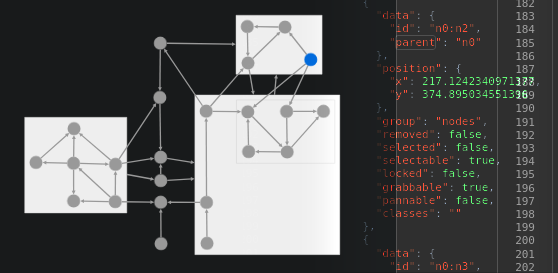
Then I notice an error from this line:
edge.target = C_to_node(target).id;
It seems an IOing was found via .node.parent: outward through the grammar but not climb to the whole line, so perhaps we're not doing the latter right...
In Code.svelte I stop look->graph causing the error:
function whatsup(view) {
look = whatsthis(view.state)
save = look.y.state
//graph = graphwhats(look)
// look = graph
}

The grammar says:
IOing[@dynamicPrecedence=10] { IOness ' ' ~IOpath }IOpath { Leg ("/" Leg)* }Leg { Sigil? Name }
A bunch of that is wrong!
Eg ~IOpath means an ambiguity marker named IOpath, not an ambiguous IOpath.
Looking Around
Then we check out this lezer playground

I load my grammar and text in and this comes up:

let parserlet warnings = capture_warnings(() => parser = buildParser(grammar))export const sthoLanguage = LRLanguage.define({// ...})
// for EditorState.create extensions[]export function stho() {let lang = new LanguageSupport(sthoLanguage)warnings and lang.warnings = warningsreturn lang}
// ta https://github.com/CodeWitchBella/codewitchbella.com/blob/main/app/routes/_nav.blog._post.2023-lezer-playground.tsxfunction capture_warnings(y) {const warnings: any[] = [];const stash = console.warn;console.warn = (w) => warnings.push(w);y()console.warn = stash;return warnings.length && warnings}
And here's how we instantiate that. So it can change we put it in a Compartment:
export let lang = langs[0];
let language = new Compartment();
// the lang are functions that return a LanguageSupport, maybe with .warnings
let lang_itself = lang()
let setlang = (lang) => {
lang_itself = lang()
view.dispatch({ effects: language.reconfigure(lang_itself) });
};
let startState = EditorState.create({
doc: value,
extensions: [
language.of(lang_itself),
And then dump any warnings:
{#if lang_itself.warnings}
<Coning t="Warnings from buildParser()" C={lang_itself.warnings} noC=1 style="background-color:#3e1e0e"/>
{/if}
I wish style was a working property on components...
So I go into Coning.svelte:
<script lang="ts">export let style = ''// ...</script>
<biggroup style={style}><!-- ... --></biggroup>
The data dumper is very text color opinionated.
If it was careful about spacey text, and shading the edge of rogue large boxes (of layout), we could easily do without all these borders, and have a tidy infinite list going on.

Looks okay for a warning.
The grammar has some noise from where I was trying to solve something.
Removing the tilde (~) from this line fixes the first three:
IOing[@dynamicPrecedence=10] { IOness ' ' ~IOpath }
We will later see that ~this means an ambiguity marker named 'this', you don't just put a tilde on some token or it would stop being a token and cut off part of your grammar, as these warnings imply.
And SunpitHead is not a token, so I take it out of here:
@precedence {Number, Title, Sunpitness, IOness, SunpitHead, Name}
We are now Warningsable!
Back To It
 was:
was:That grammar change lets us find everything.
But hang on, what about those ⚠?
Around Again
We could define a linter to pick up those ⚠, which should find non-compliant string for us!
import {syntaxTree} from "@codemirror/language"
import {linter} from '@codemirror/lint'
export function simpleLezerLinter() {
return linter(view => {
const {state} = view
const tree = syntaxTree(state)
if (tree.length === state.doc.length) {
let pos = null
tree.iterate({enter: n => {
if (pos == null && n.type.isError) {
pos = n.from
return false
}
}})
if (pos != null)
return [{from: pos, to: pos+1, severity: 'error', message: 'syntax error'}]
}
return []
})
}
And we use it in Codemirror.svelte:
import { stho,simpleLezerLinter } from "$lib/lang/stho"
// ...
let startState = EditorState.create({
// ... extensions: [
// ... simpleLezerLinter(),
// ... ],
});
And now this turns up!




I fix the grammar:

Now not only does the red squiggly go away:
 Shows us we still have ⚠
Shows us we still have ⚠
Also the 'S o ...' has become an IOing, rather than a Title!
This magically avoids the trouble I got into trying to learn about precedence.
So!
Selecting that text:
Maybe they're zero-width?
s.y.state = i_(s,save_selection_state(state))
parentc&no_node = 1
textc&no_node = 1
each t,from,to,C tft_C {
...
if (t == '⚠') {
$width = c&range.to - c&range.from
!width and console.warn("zero-width syntax error: ",{C,range:c&range})
}
}}}
Yes, two... One character after our selection starts, and two characters after our selection ends...
Hmm... There at the end of whatsthis() we don't have an obvious place to send such info...
whatsthis() makes waves of loose bits of info
mostly about the graph to build
but also, saving the selection state of the editor is a C-cmglance
which may end up being the few-second moment-mounds we grind out from the user's thrashing things through the viewport.
But that's kind of sidetracking... We can use the "inside" dir to locate the ⚠ itself:


Weirdly, I wouldn't consider this as having selected Name ("yapto") yet: Perhaps my climb to the whole line code is dodgy.
Perhaps my climb to the whole line code is dodgy.
Even weirder, adding a space causes a SunpitHead! What.

Even weirder, adding a space causes a SunpitHead! What.

Similarly, our Line fails to find "\n" before needing another Line, several times...
Any time it needs more than one space!
Now this: Smooths everything out, and the Comment comes alive:
Smooths everything out, and the Comment comes alive: Except "S o yeses..." does a SunpitHead (with underlining since tagged with t.heading1) rather than IOing again
Except "S o yeses..." does a SunpitHead (with underlining since tagged with t.heading1) rather than IOing again

From the lezer docs,
From the lezer docs,
problems with it will be thrust upon you:The error says "shift/reduce conflict" atexpression "+" expression · "+"
is for going left or right on eg "1 + 1 + 1" with the schema "expr {expr '+' expr}"
I guess it will be clear to you once you have that error.
To explicitly allow Lezer to try multiple actions at a given point, you can use ambiguity markers.
These markers, aka
~ GLR markers, are because the parser has to decide whether it is parsing a GoodStatement or a BadStatement
Apparently we must switch to using GLR parsing to accept both of them since the leading edge looks the same.
Interestingly I tried this example out, more or less, and this doesn't have any problems here:


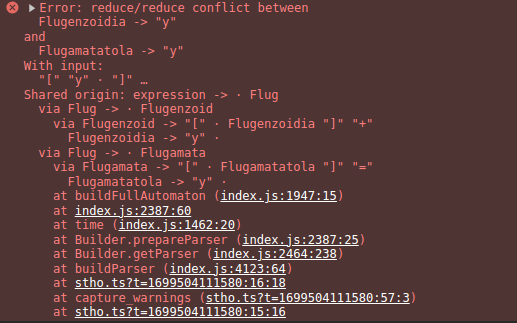


I wonder if we could make an actual permanent for-real ambiguity

But I'm not seeing any on the console...Sacre bleu! Svelte must have unplugged my warnings-gobbler... No, it looks okay:Using it was:let parserlet warnings = capture_warnings(() => parser = buildParser(grammar))Which must have just blown up at some point.I refresh the page, having been HMRing for hours now! Yay.It's back to how it was, showing every ⚠ I can reach from doing my thing on my codemirror selection.Lets use a finally block:



try {y();} catch (error) {console.warn = originalWarn;iterable_error(error)warnings.unshift(error)} finally {console.warn = originalWarn;
}
I sabotage my grammar now, so we can ensure...// if stho fails to build, just get something on screen so diag can happen// we would just use @codemirror/lang-javascript, but its object is unwritable!?function stho_substitute() {let parser = buildParser(`@tokens { else { ![\n] } }@top Program { (Lie* "\n")* }Lie { else }`)let Language = LRLanguage.define({parser: parser.configure({})})return new LanguageSupport(Language)}// for EditorState.create extensions[]export function stho() {if (!sthoLanguage) {// it failed in buildParser, with a message!hak(warnings) and debuggerlet lang = stho_substitute()warnings.unshift("Failed to buildParser()")lang.warnings = warningsreturn lang}let lang = new LanguageSupport(sthoLanguage)warnings and lang.warnings = warningsreturn lang}However,it looks empty:Until I think up this:// Errors do not make their properties iterable, somehow// perhaps this should go into Con's data climbing code, if s instanceof Errorfunction iterable_error(error) {// but we can write new properties!error.says = error.messageerror.pile = error.stack.split("\n")}I undo my sabotage,



and
we are back to seeing an ambiguous Flug turn into a Flugamata and a ⚠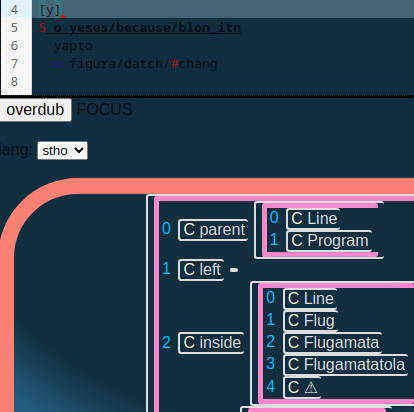
Flug { Flugenzoid | Flugamata }Flugenzoid[@dynamicPrecedence=33] { "[" Flugenzoidia "]" "+" }Flugenzoidia { "y" ~flugal }Flugamata { "[" Flugamatatola "]" "=" }Flugamatatola { "y" ~flugal }
So ambiguous Flug turn into a Flugenzoid and a ⚠
Applying dynamicPrecedence to Sunpit...
Applying dynamicPrecedence to Sunpit...
Is ineffectual.
I begin to make Flug a little more like Sunpit:
Flug { Flugenzoid | Flugamata }Flugenzoid[@dynamicPrecedence=10] { "[" Flugenzoidia "]" "+" }Flugenzoidia { Name ~flugal }Flugamata { "[" Flugamatatola "]" "=" }Flugamatatola { Title ~flugal }
And the dynamicPrecedence stops working!
It defaults to being a Flugamata again.
If I switch Name+Title for IOness+Title,
Flug { Flugenzoid | Flugamata }Flugenzoid { "[" Flugenzoidia "]" }Flugenzoidia { IOness ~flugal }Flugamata[@dynamicPrecedence=9] { "[" Flugamatatola "]" }Flugamatatola { Name ~flugal }
Text such as "[i]" and "[o]" become Flugenzoid but not "[u]" etc
Why lies in this subset of the tokens definition:
@tokens {
Title { nonnl+ }Name { (@asciiLetter | "_")+ (@asciiLetter | "_" | @digit)* }
IOness { "i" | "o" }@precedence {IOness, Number, Title, Sunpitness, Name}
}
We are favouring the IOness tokens found via Flugenzoid over the Name tokens found via Flugamata!
And, surprise, I doctored that order since we last saw it, and now the Sunpits go IOing or Heading perfectly!

So supposedly ambiguity only arises if token precedence in parallel paths is neutral?
And I hope I never get a rogue token deep in there pulling precedence awry...
Anyway, what is this!?

places = uniq(places).sort((a,b) => a-b)
You know.
Now when Heading starts with an "o", the @tokens/@precedence kicks in and it becomes a failed IOing, then (improvising recovery) a Name... Fair enough.
But lets make IOing and Sunpitness tokens a little further away by including the following space:
@tokens {IOness { "i " | "o " }Sunpitness { "S " }
Just having the space out here is not enough, it needs to be of a @precedence'd token.
IOing { IOness " " IOpath }
We now, in a Sunpit, need "o " before assuming a broken IOing.

And that's basically how it works.
Now we're here.

that Leg only comes from the C:parent-cycat, climbing from that Name.
Of the Name,Leg,Name,Leg,Name sequence,
which is inside the selection
and looking at the grammar supposedly there:
IOpath { Leg ("/" Leg)* }
Leg { Sigil? Name }
This is capturing the Leg/Name-ness at all (ie, Name being inside Leg)
it is somehow bumping into Leg when we cu.next() through to the "/" characters between the Names.
Obviously, my climb to the whole line code is dodgy.
How do other people do it? How do we fix it?
codewitchbella's
Lezer playground really communicates:

With colours...
IOpath's chartreuse is visible on the "/" between LegsLeg's fleshtone is always covered up by Name (and Sigil "#")
a limit!
to how much you can say just painting text, before complicatedly stacking the blobs of colour, so their existence is fully communicated...
With shape...
Simple syntax node business.
Legs wrapped around the Name.
The empty Line.
No text!
It would throw off the shape of course. Artist talk.
The latter is done like this:
const parser = buildParser(grammar);
# ...
const parsed = parser.parse(value);
# ...
<code className="hljs">{prettyfi(parsed.toString())}</code>
# ...
function prettyfi(tree: string) {
const lines = tree
.replace(/([(,])/g, "$1\n")
.replace(/[)]/g, "\n)")
.split("\n");
let indent = 0;
for (let i = 0; i < lines.length; ++i) {
const line = lines[i];
if (line.endsWith(")") || line.endsWith("),")) indent--;
lines[i] = " ".repeat(indent * 2) + line;
if (line.endsWith("(")) indent++;
}
return lines.join("\n");
}
Move to the next node in a pre-order traversal, going from a node to its first child or, if the current node is empty or
enteris false, its next sibling or the next sibling of the first parent node that has one.
Which sounds like squiggly traversal, so this kind of interpretation:
$cursor = tree.cursorAt(about.from, 1)
# ...
# inside, right
$found_nl = 0
$where = inside
inlezz(cursor,{
next: cu => cu.next(),
# break: cu => cu.from > about.to,
each: &cu,d{
$str = getstr(cu)
where == right && str.includes("\n") and found_nl = 1
else
found_nl and return d.not = true
cu.from > about.to and where = right
nod(where,cu)
}
})
Misses a Leg, and misses the Leg/Name-ness

moveTo(pos: number, side?: -1 | 0 | 1 = 0) → TreeCursorMove the cursor to the innermost node that covers
pos. Ifsideis -1, it will enter nodes that end atpos. If it is 1, it will enter nodes that start atpos.
That is a reasonable first move:
$cursor = tree.cursorAt(about.from, 1)
Also, apparently cursor
.node.cursor() is how you clone a cursor, and cloning is cheap, so don’t bother moving a cursor back. # start with a point
$cursor = tree.cursorAt(about.from, 1)
cursor.firstChild() and throw "cursorAt() should seek all the way in to a point"
# now zoom out to the Line
$parent = i_(s,C_('parent','-cycat',{da:{dir:1}}))
$toLine = cursor.node.cursor()
inlezz(toLine,{
# for cursor.movers() that return false if no move, so we stop
next: (cu,d) => cu.parent(),
each: (cu,d) => {
nod(parent,cu)
cu.name == 'Line' and d.not = 1
}
})
toLine.name != 'Line' and debugger
# go a few Lines ahead and back
$around = i_(s,C_('around','-cycat',{da:{dir:1}}))
map(&direction,{
direction == '' and return nod(around,toLine)
inlezz(toLine.node.cursor(),{
next: (cu,d) => cu[direction](),
each: (cu,d) => {
d.d > 1 and nod(around,cu)
d.d > Line_context and d.not = 1
}
})
},['nextSibling','','prevSibling'])

No, first lets look at these Fatshedera, who get spritzed with garlic juice:

Back at 9:42
Those black dots are bugs.
6:42, run off to the wool party because it's Friday night in Dunedin, New Zealand...Back at 9:42
Lets add direction!
// and their alignment constraints
$leinri = i_(s,C_('left-inside-right','-cycons',{type:'relativePlacementConstraint',axis:'vertical'}))
map(&n{ i_(leinri,n) }, o_(around))
$leinri = i_(s,C_('left-inside-right','-cycons',{type:'alignmentConstraint',axis:'vertical'}))
map(&n{ i_(leinri,n) }, o_(around))

I keep the dir around because otherwise,

Lets fill out some middle ground:
// fill in each Lines
# this one is deep claiming all -nodules for its structure
# the rest is all s/*:dir/*:qua
$Tree = i_(s,C_('Tree','-cytree'))
map(&ni{
# bulges in the middle
$distance = i - Linesc&middle
distance < 0 and distance *= -1
$dl = distance < 1 ? null : 4
$go = nc&leznode.cursor()
console.log(" Line "+i+" is "+distance+" so "+dl)
itelez(go,{C:Tree,each: &no,d{
$z = nod(d.C,no)
ex(d,{t:z.t,C:z})
dl && d.d > dl and d.not = 1
}})
},o_(Lines))
The docs encourage checking out what happens.
This was happening for a while::

I clear up some assumptions:
- It visits (enters) the first node, where go already is.
- ie, we give it d.C = C:Tree at the top
- and then Line etc attach via nod(d.C,no)
- You call iterate() once, then it calls your callbacks.
- To stop going in, return false, because of this strict comparison: enter(this) !== false
- $no = cur.node are stationary
- ie, they can be stored on d.no to hold its location
- the cur is the original TreeCursor again, as it moves around
And a confusion:
- The cursor moves before enter but after leave
- so as a final leave() sanity check: d.no != no.parent and debugger
Anyway, it's now going fine. I lost some of my writing around here but here's the abstractor:
# gives you a (syntaxnode,d)** traversal, scoped to the given TreeCursor
$itelez = &cur,d{
$scope = cur.node.cursor()
d.t ||= d.C?.t || 'top'
d.d ||= 1
d.no = cur.node
d.path = [d.t]
$not = 0
$verbose = 0
verbose && console.log("d.path scope: \t"+scope.from+"-"+scope.to)
$enter = &cur,{
$was = d
$no = cur.node
no.from >= scope.to and not = 1
verbose && no.from >= scope.to and console.log("d.path: "+slant([...d.path,no.name])+" from>to! "+cur.from+"-"+cur.to)
not and return false
!d.d and debugger
# d cloned for the new place
d = ex({},d,{up:d,no})
d.d++
# relying on you to set d.t here
d.each && d.each(no,d)
d.path = [...d.path,d.t]
verbose && console.log("d.path: "+slant(d.path)+" --> \t"+cur.from+"-"+cur.to)
if (d.not) {
# don't want to go in
verbose && console.log("d.path: "+slant(d.path)+" no further")
# and iterate() will not call leave
d = d.up
!d and debugger
return false
}
return 1
}
$leave = &cur,{
$was = d
$no = cur.node
not and return
# we should be tracking this on d**
# is also d.C.c.leznode
d.no != no and debugger
d = d.up
!d and debugger
verbose && console.log("d.path: "+slant(d.path)+" <--")
d.d == 1 and return
d.no != no.parent and debugger
}
cur.iterate(enter,leave)
}
Perhaps I should call it once and scope it to the range of all the Lines ...
I give Tree/*/*/* some style:
{
selector: 'node[class="ayefour"]',
style: {
'width': '90',
'height': '70',
'background-color': 'saddlebrown',
}
},
{
selector: 'node[class="ayethree"]',
style: {
'width': '70',
'height': '90',
'background-color': 'chocolate',
}
},
{
selector: 'node[class="ayetwo"]',
style: {
'width': '70',
'height': '50',
'background-color': 'goldenrod',
}
},
And:
// and their alignment constraints
$verticality = &tNc{
c ||= {order:1,align:1}
if (c.order) {
$leinri = i_(s,C_(t+'-order','-cycons',{type:'relativePlacementConstraint',axis:'vertical'}))
map(&n{ i_(leinri,n) }, N)
}
if (c.align) {
$leinri = i_(s,C_(t+'-align','-cycons',{type:'alignmentConstraint',axis:'vertical'}))
map(&n{ i_(leinri,n) }, N)
}
}
#verticality('Lines', o_(Lines))
# align a bit of Tree/Line/*/* too
$h = {}
o_path(Tree,['Tree','Line','a']) .map(({Line,a}) => {
ahk(h,['Line'],Line)
ahk(h,['a'],a)
# make a /b? leg on the above
map(&b{
ahk(h,['b'],b)
}, o_(a))
})
$classes = ['ayefour','ayethree','ayetwo']
$classes_add = &nk{
fatal.ispi(n,'nodule')
$da = nc&da ||= {}
if (!isar(da.classes)) {
da.classes = da.classes ? da.classes.split(" ") : []
}
da.classes.push(k)
}
each iN h {
verticality('Tree-layer-'+i, uniq(N), )
$cla = classes.shift()
map(n => classes_add(n,cla),N)
}

Version 3?
and layout:dagre:

Tree/Line* have a notch filter:
# bulges in the middle
$distance = i - Linesc&middle
distance < 0 and distance *= -1
$dl = distance < 1 ? null : 2
So when we go down to the Flug:

One of the Lines isn't being styled. o_path() of course requires rows to have all given columns - which are really just levels in the tree.
Another recursion method:
# align a bit of Tree/Line/*/* too
$h = {}
inlace(Tree,{grab:&sd{
!d.d || d.d > 3 and return
ahk(h,[d.d],s)
}})
I suspect syntax nodes should not edge to text of a deeper syntax node.
It can get wooly:
So lets:
# establish a dominant syntaxnode, for fewer edge:te
$ow = nc&owner
!ow || ows&depth < s&depth and nc&owner = C
We could also collect them all and give closer coupling to the deepest ones via Divisor to compute edge forces, but lets not.

The slinking around of the text is better.
Perhaps I could do with a left-of constraint down Tree/**, except the deepest node or two?
In layout:dagre it shows improved subsidiarity now syntax roots are not claiming so much text:


Hmm...
Lets align the Lines!
# align Line//textnodes
map(&Line,i{
$texts = []
map(([C,n]) => {
C == Line and texts.push(n)
},syntex)
texts.length < 2 and return
horizontality("Line-"+i, texts)
console.log({Line,texts})
},o_(Lines))
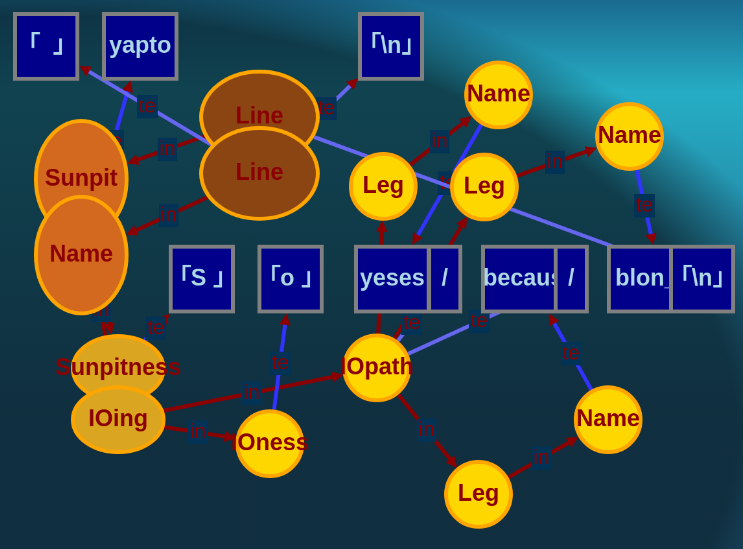
And manages to tangle itself.
Lets add the Line to the text alignment:
horizontality("Line-"+i, [Line,...texts])
And:
# ignore all \n
grop(([C,n]) => {
n.t == '「\\n」' and return nc&no_node = 1
},syntex)

Without text alignment, only left-right order:
horizontality("Line-"+i, [Line,...texts],{order:1})
# edges along texts
$texord = i_(s,C_('text order'+i,'-cyedge',{da:{class:'along',label:'ne'}}))
map(&n{ i_(texord,n) }, texts)
Is not great:

It seems this graph doesn't have much to gain from being a graph.
Here's this:
# also, make an indented name pile
graph.nodetree = ''
inlace(dir,{grab:&sd{
# not the container C:Tree
d.d < 1 and return
graph.nodetree += indent(d.d)+s.t+"\n"
}})
{#if graph?.nodetree}
<details>
<summary>nodetree</summary>
<pre>{graph.nodetree}</pre>
</details>
{/if}

This could use the &Piing system to crunch an okay boxy layout to give lots of Codemirror decorations...


The end.
No comments:
Post a Comment