
A simple graph of the text...
make the boxes wide enough
I will specify some data on the node (texty) to hold how many characters long it is
// the text split by syntax nodes
# intervals of text to be many-edged to syntax nodes
$places = []
each t,from,to,C tft_C {
places.push(from*1, to*1+1)
}}}
places = uniq(places.sort())
$text = i_(s,C_('text','-cycat'))
$from = null
each i,to places {
# sacrifice first to to be a from, do the rest in pairs
from == null and from = to; continue
$cur = {name: getstr({from,to}), from,to}
textnod(text, cur,
# style
{da: {texty:cur.name.length}}
)
from = to
}
textnod() at some point does node.data = ex({name:C.t},c&da||{},da||{})
{
selector: 'node[data.texty]',
style: {
'width': 'data(data.texty) em',
'shape': 'rectangle',
'color': 'lightblue',
'line-color': 'lightblue',
'background-color': 'darkblue',
'border-color': 'gray',
}
},
This does not appear to alter the width...
The docs are vague on its use in style strings but I have seen it done (somewhere?) They say
data() specifies a direct mapping to an element’s data field Lets make sure we are here:
'label': 'Blah',

Well yeah.
'label': 'Blah data(data.texty)',

Hmm.
'label': 'data(data.texty)',

Aha! The data(...) thing must be alone in that string.
As usual, make code where complexity arises:
'width': ele => ((ele.data('data.texty') ?? 2)*0.5+1)+'em',
'text-wrap': 'none',

?? is a defined-or, meaning here we may take 0 over 2.
I'll pipe the node.name through this for raku-like string quotes:
$textfilter = &s{
$spacearound = s.match(/^\s|\s$/)
$nl = s.includes("\n")
spacearound || nl and s = '「'+s+'」'
nl and s = s.replaceAll("\n","\\n")
return s
}

This shows spaces in odd places. \n means down-to-the-next-line-now in plain text.
The content of the above graph is generated in letz.git src/lib/Le.ts 53d80e5a1c1f75ef0, in a function called whatsthis
Cytoscape fabricates layouts for vaguely structured graphs.
Pretty amazing.
Lots of life happens in forms that do not obviously translate back to space, so we need a general stuff-piler to mount the life inside.
It solves constraints, mostly that things "fit" in the usual sense, eg none of those edges overlap!
So, adding more edges...
$texord = i_(s,C_('text order','-cyedge',{da:{class:'along',label:'ne'}}))
map(&n{ i_(texord,n) }, o_(text))

Ah, it often folds the tail of a chain of things, sometimes even just one of them.
A similar shape is seen in the rest of the graph we haven't yet joined to:

We have a selection targeting into Program/Line/Sunpit/SunpitHead/Title.
We look around, using cursors: .next() .parent(), etc
Some nodes have alignment constraints nice.
Lets add edges
# relate to any non-text node...
each t,from,to,C tft_C {
t == 'text' and continue
t == 'Line' and console.log([C.t,c&range])
o_(text) .map(&n{
# find range overlap: syntaxnode:C textnode:n
# < surely part of codemirror somewhere?
$overlap = range_overlaps(nc&range,c&range)
#C.t == 'Title' and console.log([C.t,overlap,c&range,nc&range,C,n])
!overlap and return
$classes = ['along']
!range_contained(nc&range,c&range) and 1
classes.unshift('broke')
# quite a few of these
# only two nodes each since they don't traverse like -cyedge/* is designed to
# < hanging a link-to C on the -cycat/$C-nodule/-cylink
# supposing we can impose that on there...
# we might also group things elsehow
$tetosy = i_(s,C_('text to syntax','-cyedge',{da:{class:classes,label:'te'}}))
map(&n{ i_(tetosy,n) }, [C,n])
})
}}}
# ...
# if r2 shares any positions with r1
$range_overlaps = (r1,r2) => r1.from <= r2.to && r1.to >= r2.from
# if r2 fits inside r1
$range_contained = (r1,r2) => r1.from <= r2.from && r1.to >= r2.to

Hmm.
I found these range comparisons pretty bamboozling to code by the way.
Head injury? Lead? Weed? Traffic? What's doing you in?
When you run yourself out of visual imagination...
Switching layout engine to dagre shows that better, using more space:

Many syntaxnodes per bit of text! The grammar recurses out into space - down those 'up' edges there.
Lets make less links (by the way broke isn't working for me here so don't take this as advice)
!range_contained(nc&range,c&range) and return
classes.unshift('broke')

But what we really need to do is lose the text + parent dirs:
parentc&no_node = 1
textc&no_node = 1
And where we C:look** into cytoscape we just avoid them:
$mkedge = &source,target,etc{
grap(n => nc&no_node, [source,target]) and return
Etc, grap() is from lib/Y/Pic.ts, check it out:# false if empty, like &za$grap = &cs{$N = grep(c,s)return hak(N) && N}

Lets make text relating more inclusive again:
!range_contained(nc&range,c&range) and 1

It's noisy again.
I try to sort it out:
$seem = 'along'
!range_contained(nc&range,c&range) and seem = 'broke'
# ...
$tetosy = i_(s,C_('text to syntax','-cyedge',{da:{class:seem,label:'te'}}))
So only node.classes can be an array? There may be no edge.classes, only edge.class?
# < seems to be no edge.classes, only edge.class
I also struggle with this:
# < figure out why+how node.* and node.data.* are different things
A random aside also from mknode(): # < doing this stuff causes a loop somewhere that freezes devtools
# node.data.id = delete node.id
These could easily be bugs to report.
I sort out those classes, avoiding dotted lines, opting for two strengths of lavender:
{
selector: 'edge[class="texty"]',
style: {
'line-color': '#33f',
}
},
{
selector: 'edge[class="textybroke"]',
style: {
'line-color': '#66e',
}
},

In layout:dagre, I begin to suspect the strong text connection (range_contained()) is the wrong way round:
- Program doesn't contain any text yet overlaps with everything.
- Sunpitness|Title|SunpitHead contain their text yet their text contains only them.
!range_contained(c&range,nc&range) and classes = 'textybroke'

Also we must have some off-by-one going on:
- Line seems to include a \n from the previous line.
Hmm... When I select one character: The resumable state save says:
The resumable state save says:

I may have been told this at some point. I adjust:
# if r2 shares any positions with r1
$range_overlaps = (r1,r2) => r1.from <= r2.to-1 && r1.to-1 >= r2.from
# if r2 fits inside r1
$range_contained = (r1,r2) => r1.from <= r2.from && r1.to >= r2.to
And also drop the Program dir, which of course links everything:
each t,from,to,C tft_C {
t == 'Program' && ispi(C,'nodule') and c&no_node = 1
}}}
Yes, there are lots of closing brackets, the each compiler leaves that to you when you traverse an index wider than two.

And so all of the text<->syntaxnode edges are fully contained, of course, since we made these text nodes anywhere syntaxnodes range.
So perhaps seeing if the text is the entire syntax node is what we can show...
By switching these arguments back around.
It isn't very obvious that the first should contain the second.
!range_contained(nc&range,c&range) and classes = 'textybroke'

Now I think it's time to switch back on an extra layer of edges:
# and cursor.node.parent-ward from every lezer node we have
# we seem to skip some things doing cursor.parent()
# eg also linkage of cu(.name=Sunpitness).node.parent(.name=Sunpit)
# < we can leave out any of these edge:ou that duplicate with edge:up
# this can be done easily once cy data up til now is loaded...
# ie add some more by querying data up til then
# and we want to stream that situation...
each t,from,to,C tft_C {
#continue
!ispi(C,'nodule') and debugger
# every lezer node we have (not a cursor on a node as above)
$node = c&leznode
# can start a series of edges
$extras = C_('extrapolations','-cyedge',{da:{label:'ou',class:'outward'}},{via:'node'})
$la_node = node
inlezz(node,{
each: &node2,d{
# not node itself
d.d == 1 and return
$range = {from:node2.from,to:node2.to}
# stop when we arrive at lezer nodes we have?
# < Compression could prefer fewer -cyedge with longer /*
!extrass&z and nod(extras,la_node,{})
nod(extras,node2,{})
ahsk(tft_C, node2.name,range.from,range.to) and return d.not = 1
},
next_returns: true,
next: no => no.parent,
})
# ground if populated
extrass&z and i_(s,extras)
}}}

$text_unseen = [...o_(text)]
$dont_see = {text:1,Program:1}
each t,from,to,C tft_C {
dont_see[t] and continue
o_(text) .map(&n{
# find range overlap: syntaxnode:C textnode:n
# < surely part of codemirror somewhere?
$overlap = range_overlaps(c&range,nc&range)
!overlap and return
grop(n, text_unseen)
Taking them out if seen from a syntaxnode, then hiding the rest:
each in text_unseen {
nc&no_node = 1
}

Tidy. And ugly!
I wish I could figure out node.parent, for composite graphs! eg:
Lets try and set parent on the graph live. I have this listener:
cy.on('select', 'node', () => selection_changed())
To:
function selection_changed() {
window.eles = cy.$('node:selected')
}
So I can devtools things:



Wait does it want the element object itself?

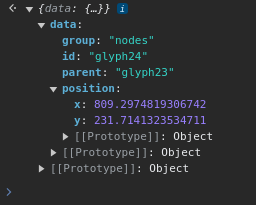
A node’s parent can be specified when the node is added to the graph, and after that point, this parent-child relationship is immutable via
ele.data().Aha! Well, it's there when we load the nodes...

if (node.data?.parent) node.parent = node.data.parent; console.log("NODE parent",node)

It's able to be paused still though, some other loops I found need Ctrl+Esc in a chrome|brave window other than the one that is dying.
And so the prospect of lovely overlapping diagramatics (parenthood) assails me not.
Cytoscape.js is unsmoothed by garden variety TLC. Its attendance has probably been a series of academic idea space grabs deep in the theory.
Looking around, here are some compound nodes and some ink flowing yay far downstream, nice concept. Apparently this has something to do with biology. You can almost see the frog legs here:

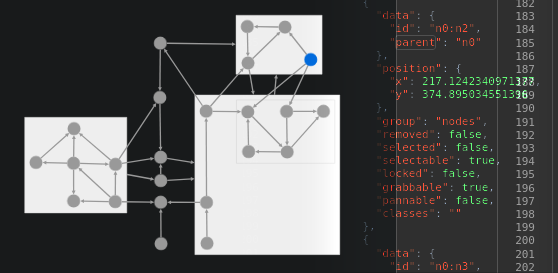
Then I notice an error from this line:
edge.target = C_to_node(target).id;
It seems an IOing was found via .node.parent: outward through the grammar but not climb to the whole line, so perhaps we're not doing the latter right...
In Code.svelte I stop look->graph causing the error:
function whatsup(view) {
look = whatsthis(view.state)
save = look.y.state
//graph = graphwhats(look)
// look = graph
}

The grammar says:
IOing[@dynamicPrecedence=10] { IOness ' ' ~IOpath }IOpath { Leg ("/" Leg)* }Leg { Sigil? Name }
A bunch of that is wrong!
Eg ~IOpath means an ambiguity marker named IOpath, not an ambiguous IOpath.
No comments:
Post a Comment